# 最优传输
如何用最少的代价将一个质量分布转为另一个质量分布
## Monge
Let μ and ν be two measures in $\mathbb{R}^d$. The optimal transport problem by Monge is defined as
$$\begin{equation}
{\arg \min }_{T:{T}_{\sharp }\mu = \nu }\,\,{{\mathbb{E}}}_{X \sim \mu }\parallel X-T(X){\parallel }_{2}^{2},
\end{equation}$$
where $T$ corresponding to the smallest cost is the optimal transport map.
${T}_{\sharp }$是前推算子,让${T}_{\sharp }$的作用对象是$\mu$,表示吧$\mu$推到$v$
通俗地说,保测度的意思就是你从$X$搬多少重量的东西(在$Y$的度量下) 到$X$的某个区域,这个区域在$Y$的度量下也得有这么多重量。
但是映射的定义限制了不能实现一对多的操作,以至于Monge问题不一定有解。
我们可以让质量“可分”,即以概率的形式去进行“移动”。这就是Kantorovich问题。
## kantorovich
$$\begin{equation}
W(\mu ,\nu )=\mathop{\min }\limits_{\gamma \in {{\Gamma }}(\mu ,\nu )}{{\mathbb{E}}}_{(X,Y) \sim \gamma }\parallel X-Y{\parallel }_{2}^{2},
\end{equation}$$
where the polytope Γ(μ, ν) is $\{\gamma \in {{\mathbb{R}}}_{+}^{n\times m},\gamma {{{{\bf{1}}}}}_{m}=\mu ,{\gamma }^{\top }{{{{\bf{1}}}}}_{n}=\nu \}$
, describes the set of all couplings (or joint distributions) γ between μ and ν.

Wasserstein

Kantorovich对偶
Problem (2) denotes the primal formulation of optimal transport. Kantorovich also introduces its corresponding dual54, which is a constrained concave maximization problem defined as
$$\begin{equation}
W(\mu ,\nu )=\mathop{\max }\limits_{(g,f)\in {{{\Phi }}}_{c}}{{\mathbb{E}}}_{\mu }[g(x)]+{{\mathbb{E}}}_{\nu }[f(y)],
\end{equation}$$
where the set of admissible potentials is${{{\Phi }}}_{c}:=\left\{(g,f)\in {L}^{1}(\mu )\times {L}^{1}(\nu ):g(x)+f(y)\le \frac{1}{2}\parallel x-y{\parallel }_{2}^{2},\forall (x,y)d\mu \otimes d\nu \, {{{\rm{a.e.}}}}\right\}$
这个论文里面给出来的对偶形式完全看不懂
首先我把我没搞懂的几个问题整合一下
### 第一:
$$\begin{equation}
W(\mu ,\nu )=\mathop{\min }\limits_{\gamma \in {{\Gamma }}(\mu ,\nu )}{{\mathbb{E}}}_{(X,Y) \sim \gamma }\parallel X-Y{\parallel }_{2}^{2},
\end{equation}$$
和$1/2(||x-y||^2_2)$有什么关联:
写的公式是
$$
W(\mu ,\nu )=\min_{\gamma \in \Gamma(\mu ,\nu )}\,\mathbb{E}_{(X,Y)\sim \gamma}\, \|X-Y\|_2^{2},
$$
而在对偶形式里,约束条件变成
$$
f(x)+g(y) \le \tfrac{1}{2}\|x-y\|_2^2.
$$
你想知道为什么这里突然冒出了一个 **$ \tfrac{1}{2}$**。
---
#### 关键点:代价函数的选择
在最优传输(OT)里,代价函数 $c(x,y)$ 是 **你自己定义的**。
* 如果 primal 里用的是
$$
c(x,y) = \|x-y\|_2^2,
$$
那么 dual 就会出现
$$
f(x)+g(y) \le \|x-y\|_2^2.
$$
* 如果 primal 里用的是
$$
c(x,y) = \tfrac{1}{2}\|x-y\|_2^2,
$$
那么 dual 就会出现
$$
f(x)+g(y) \le \tfrac{1}{2}\|x-y\|_2^2.
$$
也就是说,**那个 $\tfrac{1}{2}$ 并不是推导出来的,而是作者一开始就选择了带 $\tfrac{1}{2}$ 的代价函数**。
---
#### 为什么很多文献喜欢用 $\tfrac{1}{2}\|x-y\|^2$?
因为这样在推导 **Brenier 定理**(凸势函数的梯度给出最优传输映射)时,形式更漂亮:
* 若代价是 $\tfrac{1}{2}\|x-y\|^2$,最优传输可以写成
$$
T(x) = x - \nabla f(x),
$$
其中 $f$ 是个凸函数。
* 如果没有这个 $\tfrac{1}{2}$,就会多一个 “2” 的因子,让公式看起来比较丑。
所以这个 $\tfrac{1}{2}$ 主要是**规范化(convention)**,不影响最优传输的本质。
### 第二个,直观的理解一下对偶问题:
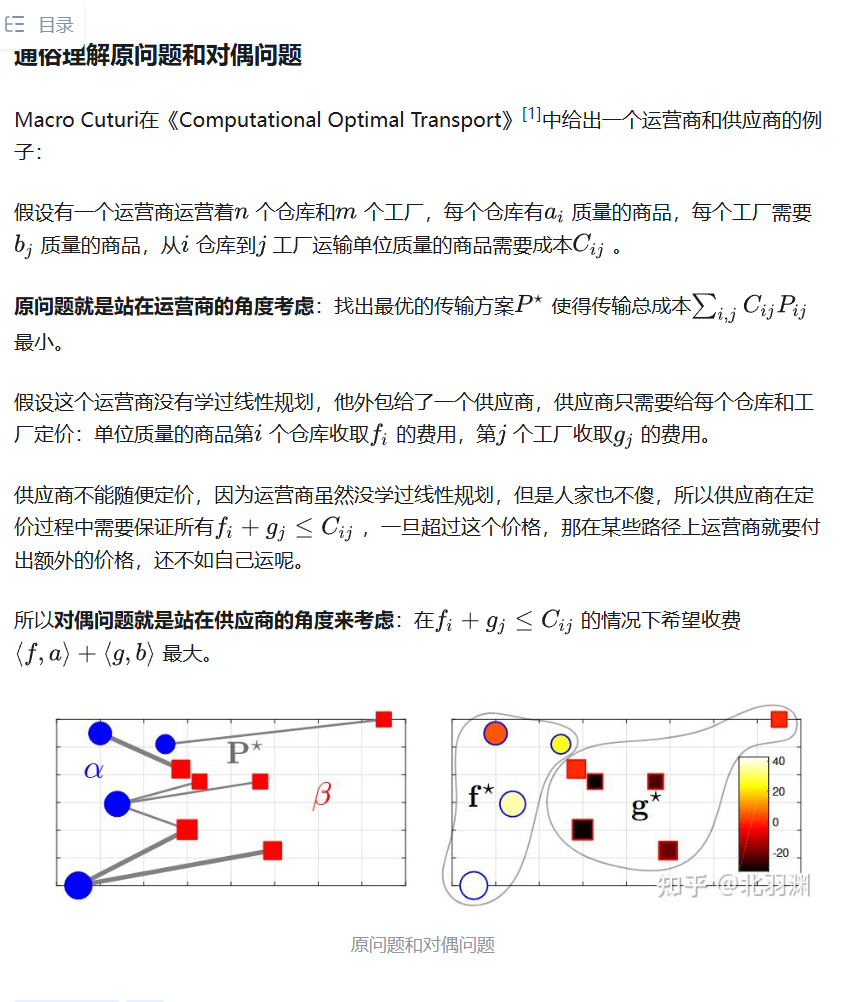
### 第三个,怎么利用拉格朗日对偶形式
#### 2. 拉格朗日对偶思路 (Lagrangian Duality)
为什么会出现对偶形式(带 $g(x)+f(y) \le c(x,y)$ 的公式)呢?这是 **拉格朗日对偶**的典型应用。思路分几步:
---
###### (1) 原始问题 (Primal)
写成积分形式:
$$
\min_{\gamma \ge 0} \int c(x,y)\, d\gamma(x,y)
$$
约束:
$$
\int d\gamma(x,y) = \mu(x), \quad \int d\gamma(x,y) = \nu(y).
$$
也就是说:
* $\gamma$ 的 $x$-边际是 $\mu$;
* $\gamma$ 的 $y$-边际是 $\nu$。
---
###### (2) 给约束加拉格朗日乘子
用函数 $g(x)$、$f(y)$ 作为拉格朗日乘子,写成拉格朗日函数:
$$
L(\gamma, g,f) = \int c(x,y)\, d\gamma(x,y)
+ \int g(x)\, \big( d\mu(x) - \int d\gamma(x,y)\big)
+ \int f(y)\, \big( d\nu(y) - \int d\gamma(x,y)\big).
$$
展开后得到:
$$
L(\gamma,g,f) = \int g(x)\, d\mu(x) + \int f(y)\, d\nu(y) + \int \big(c(x,y) - g(x) - f(y)\big)\, d\gamma(x,y).
$$
---
###### (3) 取 inf over $\gamma$
* 我们希望 $\min_\gamma L(\gamma,g,f)$ 是良定义的。
* 如果 $c(x,y) - g(x) - f(y) < 0$ 在某处成立,那么对那个地方的 $\gamma(x,y)$ 可以趋向无穷大,就会让 $L$ 趋向 $-\infty$。
* 为了避免这种情况,必须要求
$$
g(x) + f(y) \le c(x,y), \quad \forall (x,y).
$$
这就是你看到的条件。
于是 $\inf_\gamma L(\gamma,g,f) = \int g\, d\mu + \int f\, d\nu$,如果满足约束,否则是 $-\infty$。
---
###### (4) 得到对偶问题 (Dual)
所以对偶问题就是:
$$
\sup_{g,f} \;\; \int g(x)\, d\mu(x) + \int f(y)\, d\nu(y) \quad
\text{s.t.}\quad g(x)+f(y)\le c(x,y).
$$
这就是 **Kantorovich 对偶形式**。
## Villani对于这个dual问题的转化
$$\begin{equation}
W(\mu, \nu)= \underbrace{\frac{1}{2}{\mathbb{E}}\left[\|x\|_{2}^{2}+\|y\|_{2}^{2}\right]}_{{\mathcal{C}}_{\mu, \nu}}-\min _{f \in {\tilde{\mathrm{\Phi}}}} {\mathbb{E}}_{\mu}[f^{*}(x)]+{\mathbb{E}}_{\nu}\left[f(y)\right],
\end{equation}$$
where
$\widetilde{{{\Phi }}}$ is the set of all convex functions in $L1(dμ) × L1(dν)$, L1(μ):={g is measurable & ∫gdμ < ∞} , ${f}^{* }(x)=\mathop{\max }\nolimits_{y}\langle y,x\rangle -f(y)$ is f’s convex conjugate, and the optimal transport map transforming μ into ν corresponds to the gradient of $f*$, i.e., $T = ∇ f*$. We can recover the optimal transport plan via $\gamma ={(\nabla {f}^{* }\times {{{\rm{Id}}}})}_{\sharp }\mu$
. Theorem 2.9 by Villani23 then proves the existence of an optimal pair $(f, f*)$ of lower semi-continuous proper conjugate convex functions on $\mathbb{R}^n$
minimizing (3).
这一大段我就看不懂了,我也不想看懂了。
但还是顺便理解一下凸共轭
### 凸共轭
好问题 👍。**凸共轭 (convex conjugate)** 是凸分析里的一个核心概念,直觉上它描述了一个函数在所有可能“斜率”下的“最佳线性近似”。我帮你拆开:
---
1.定义
给定一个函数 $f:\mathbb{R}^d \to \mathbb{R}\cup\{+\infty\}$,它的 **凸共轭** $f^*$ 定义为:
$$
f^*(x) = \sup_{y \in \mathbb{R}^d} \{\langle x, y \rangle - f(y)\}.
$$
* $\langle x, y\rangle$ 是一个线性函数(斜率由 $x$ 决定)。
* $\langle x, y\rangle - f(y)$ 表示“线性函数 $\langle x, y\rangle$”减去原函数的值。
* 对所有 $y$ 取最大值,得到的就是 $f^*(x)$。
👉 换句话说:
**$f^*(x)$ 衡量的是:斜率为 $x$ 的线性函数,能在多大程度上“支撑”或“逼近”原函数 $f$。**
因此,凸共轭可以理解为 **“函数的斜率空间里的重新表达”**。
* 如果 $f(y)$ 是一个凸函数,那么在平面上可以画很多条直线(仿射函数):
$$
\ell_x(y) = \langle x, y\rangle - b
$$
想要让直线 $\ell_x$ 永远在 $f(y)$ 下面,$b$ 必须足够大。
* 那么 $f^*(x)$ 正是这个最小 $b$ 的负数,也就是“用斜率 $x$ 的直线支撑函数 $f$ 的代价”。
所以 **共轭操作就是把函数换一种坐标:从“点空间 (y)”切换到“斜率空间 (x)”**。
例1:二次函数
$$
f(y) = \tfrac12\|y\|^2.
$$
计算共轭:
$$
f^*(x) = \sup_y \{\langle x,y\rangle - \tfrac12\|y\|^2\}.
$$
最大值出现在 $y=x$,所以:
$$
f^*(x) = \tfrac12\|x\|^2.
$$
➡️ 二次函数的共轭还是自己。
---
例2:指示函数
若
$$
f(y) = \begin{cases}
0 & y\in C, \\
+\infty & y \notin C,
\end{cases}
$$
则
$$
f^*(x) = \sup_{y\in C} \langle x,y\rangle,
$$
这就是集合 $C$ 的 **支撑函数**。
---
* **双共轭**:$f^{**}=f$ (若 $f$ 是凸的、下半连续)。这叫 **Fenchel-Moreau 定理**。
* 共轭把“点值视角”转为“斜率视角”,特别适合与最优传输里的**梯度映射**搭配。
* 在 OT 里,最优传输映射 $T=\nabla f^*$,正是利用了“凸函数的梯度”能编码一个单值映射的性质。
**总结**:
凸共轭 $f^*$ 就是把函数 $f$ 从“点空间”转到“斜率空间”的表达,它告诉我们用斜率为 $x$ 的线性函数去支撑 $f$ 的最优程度。它在几何上对应支撑函数,在优化与 OT 里是把函数与映射(梯度)联系起来的桥梁。
##
$$\begin{equation}
W(\rho_c, \rho_k)=\max\limits_{\substack{f \in {\tilde{\mathrm{\Phi}}} \\ f^{*} \in L^{1}(\rho_k)}} \min\limits_{g \in {\tilde{\mathrm{\Phi}}}} {\mathcal{C}}_{\rho_c, \rho_k} \underbrace{-{\mathbb{E}}_{\rho_c}[\langle x, \nabla g(x)\rangle-f(\nabla g(x))] - {\mathbb{E}}_{\rho_k}[f(y)]}_{{\mathcal{V}}_{\rho_c, \rho_k}(g, f)}.
\end{equation}$$
好的,我来逐句帮你翻译并解释这段话:
---
$$
W(\mu, \nu)= \underbrace{\frac{1}{2}{\mathbb{E}}\left[\|x\|_{2}^{2}+\|y\|_{2}^{2}\right]}_{{\mathcal{C}}_{\mu, \nu}}-\min _{f \in {\tilde{\mathrm{\Phi}}}} {\mathbb{E}}_{\mu}[f^{*}(x)]+{\mathbb{E}}_{\nu}\left[f(y)\right],
$$
其中:
* **$\widetilde{\Phi}$** 表示所有凸函数的集合,这些函数属于 $L^1(d\mu) \times L^1(d\nu)$。
* $L^1(\mu):={g \ \text{是可测函数 且} \int g , d\mu < \infty }$,即在测度 $\mu$ 下可积的函数集合。
* **$f^*(x)=\max_y \langle y, x \rangle - f(y)$** 是函数 $f$ 的 **凸共轭(convex conjugate)**。
* 将 $\mu$ 转换为 $\nu$ 的最优传输映射(optimal transport map)对应于 $f^*$ 的梯度,即
$$
T = \nabla f^*.
$$
* 我们可以恢复最优传输计划(transport plan):
$$
\gamma = (\nabla f^* \times \mathrm{Id})_\sharp \mu,
$$
其中 $(\cdot)\_\sharp \mu$ 表示 **推前测度(pushforward measure)**。
* Villani 的《最优传输理论》(Theorem 2.9)证明了:在 $\mathbb{R}^n$ 上,存在一对最优的 $(f, f^*)$,它们是下半连续(lower semi-continuous)、适当的(proper)且互为凸共轭函数,并且它们能够最小化上式中的优化问题 (3)。