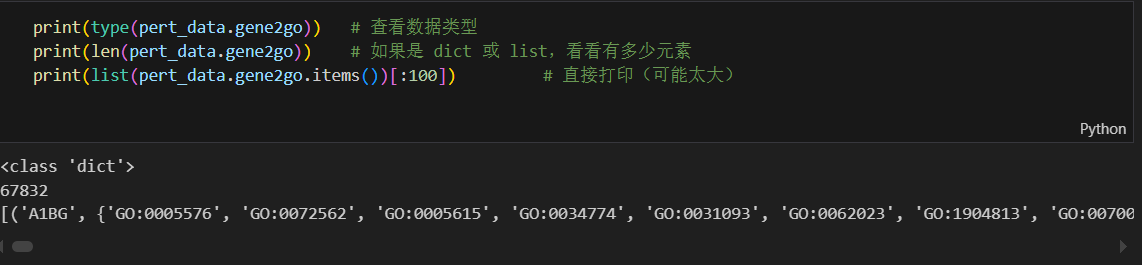
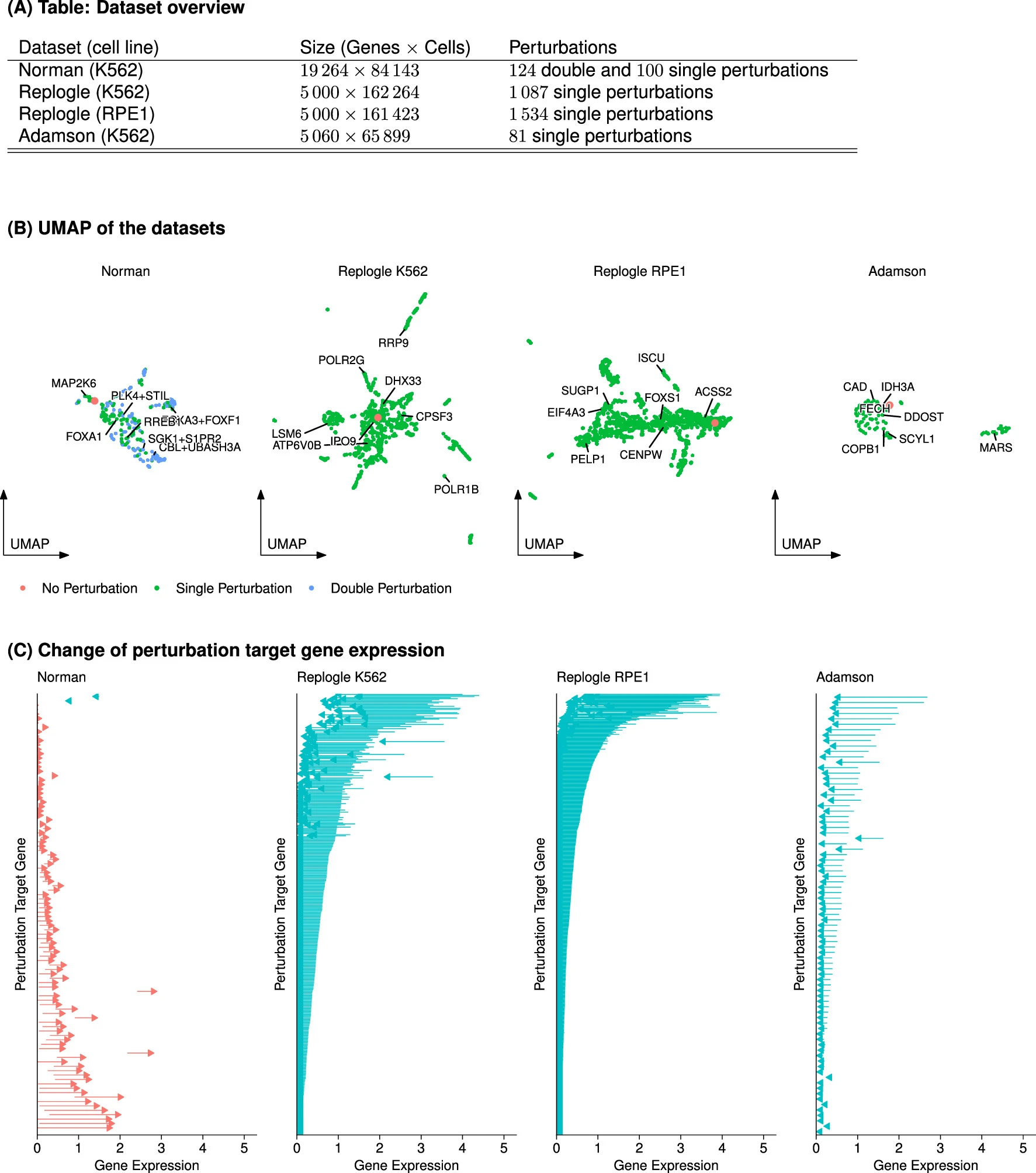
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
|
def get_simulation_split(self,pert_list,trian_gene_set_size=0.85,combo_seen2_train_frac = 0.85,
seed = 1 , test_set_perts = None , only_test_set_perts = False ) :
"""
pert_list -> unqiue_perts
这里的unique_perts代表了不重复的扰动
"""
unique_pert_genes = self.get_genes_from_perts(pert_list)
"""
这里的unique_pert_genes代表了不重复扰动中不重复的基因
"""
pert_train = []
pert_test = []
np.random.seed(seed=seed)
if only_test_set_perts and ( test_set_perts is not None) :
ood_genes = np.array(test_set_perts)
train_gene_candidates = np.setdiff1d(unique_pert_genes,ood_genes)
else:
train_gene_candidates = np.random.choice ( unique_pert_genes,
int(len(unique_pert_genes) * trian_gene_set_size ) , replace = False)
if test_set_perts is not None:
num_overlap = len(np.intersect1d(train_gene_candidates,test_set_perts))
train_gene_candidates = train_gene_candidates[~np.isin(train_gene_candidates,test_set_perts)]
ood_genes_exclude_test_set = np.setdiff1d(unique_pert_genes,np.union1d(train_gene_candidates,test_set_perts))
train_set_addition = np.random.choice(ood_genes_exclude_test_set,num_overlap,replace=False)
train_gene_candidates = np.concatenate((train_gene_candidates,train_set_addition))
ood_genes = np.setdiff1d(unique_pert_genes,train_gene_candidates)
pert_single_train = self.get_perts_from_genes(train_gene_candidates,pert_list,'single')
pert_combo = self.get_perts_from_genes(train_gene_candidates,pert_list,'combo')
pert_train.extend(pert_single_train)
combo_seen1 = [x for x in pert_combo if len([t for t in x.split('+') if
t in train_gene_candidates]) == 1]
pert_test.extend(combo_seen1)
pert_combo = np.setdiff1d(pert_combo,combo_seen1)
np.random.seed(seed=seed)
pert_combo_train = np.random.choice(pert_combo,int(len(pert_combo)*combo_seen2_train_frac),replace=False)
combo_seen2 = np.setdiff1d(pert_combo,pert_combo_train).tolist()
pert_test.extend(combo_seen2)
pert_train.extend(pert_combo_train)
unseen_single = self.get_perts_from_genes(ood_genes,pert_list,"single")
combo_ood = self.get_perts_from_genes(ood_genes,pert_list,'combo')
pert_test.extend(unseen_single)
combo_seen0 = [x for x in combo_ood if len([t for t in x.split('+') if t in train_gene_candidates]) == 0]
pert_test.extend(combo_seen0)
assert len(combo_seen0) + len(combo_seen1) + len(unseen_single) + len(pert_train) + len(combo_seen2) == len(pert_list)
return pert_train,pert_test,{'combo_seen0': combo_seen0,
'combo_seen1': combo_seen1,
'combo_seen2': combo_seen2,
'unseen_single': unseen_single}
|