小毕设要求实现的论文,还挺新
这是知乎上的归纳总结,本文基本不会参考知乎上的那篇,准备先自己理解总结一遍再看看其他人怎么写的
原文地址和代码知乎上都有引用
# Abstract
Current methods predominantly rely on labeled domain-specific video datasets,which limits the cross-domain generalization of learned similarity embeddings.
MASA, a novel method for robust instance association learning, acapable of mathching any objects within videos across diverse domains without tracking labels.
它的算法大致是用 SAM 先跑个输出域,然后利用它设计的算法 MASA 去跟踪,这种联合的算法不需要先前目标示例,意思是即使在从未见过目标的情况下也能跟踪他,而且效果比标记的数据更好。
研究的问题是 Multiple Object Tracking (MOT)
# Introduction
先描述了一下现有方法的局限性:需要标注,普遍能力不强
他们模型的目标是设计一个方法能够匹配各种物体 (objects) 和领域 (regions),然后叫这种方法与其它图像检测与分割的方法结合,帮助它们检测跟踪的目标
它们利用了 SAM 得到的丰富的物体外表特征与形状信息,使其与 extensive data transformation 结合,得到了很强的实例相关性
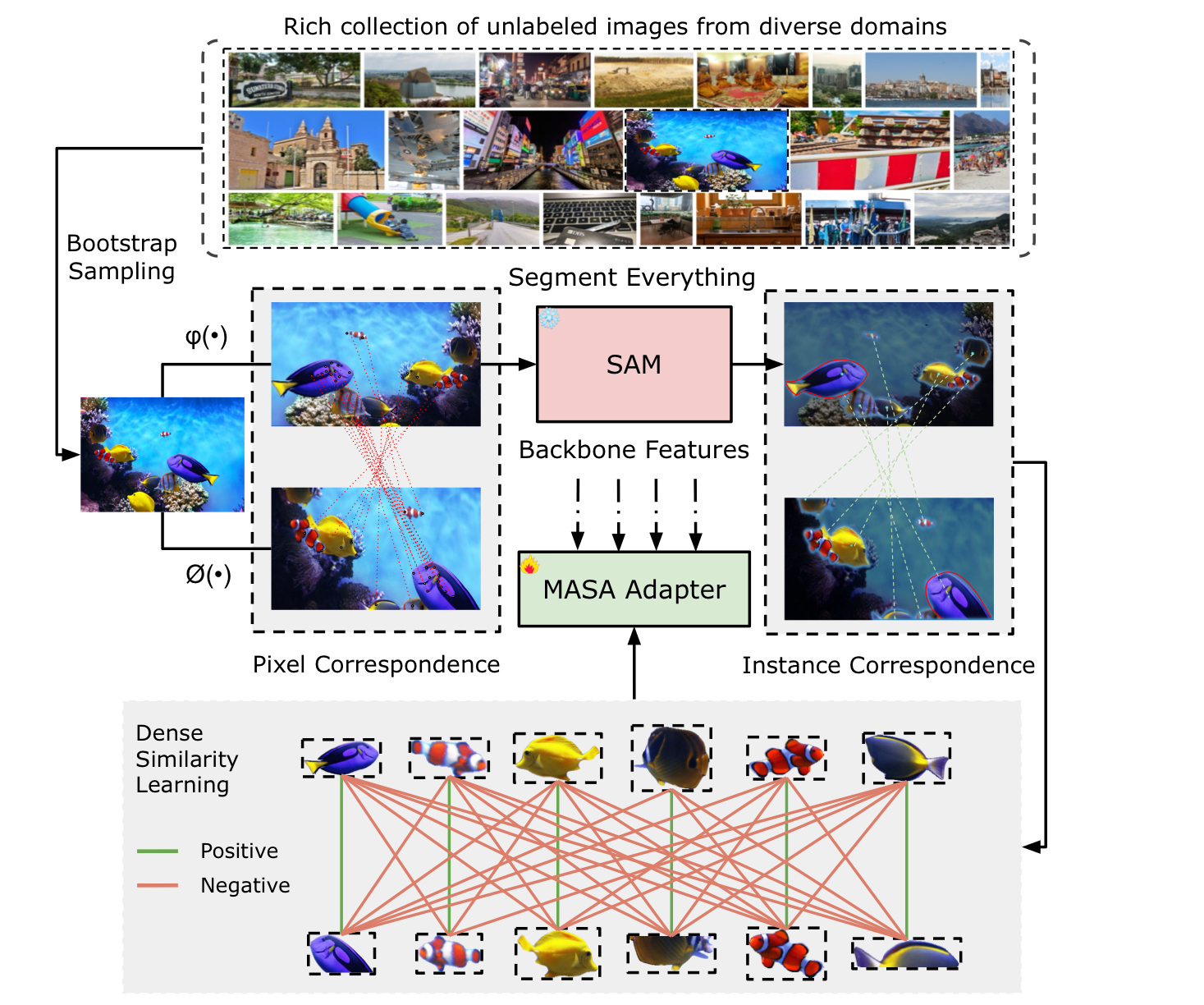
MASA adapter empowers the foundational models to track any objects they have detected, and show zero-shot tracking ability in complex domains.
Applying different geometric transformations to the same image gives automatic pixel-level correspondence in two views from the same image.
SAM's segmentation ability allows for the automatic grouping of pixels from the same instance, facilitating he conversion of pixel-levek to instance-levek correspondence.
根据上面两行的操作我们得到了一个 self-training pipeline,然后利用定义的 Adapter:MASA 去追踪检测到的物体。
更进一步,提出了一个 multi-task training pipeline that jointly performs the distillation of SAM's detection knowledge and instance similarity learing.
最后他们做了个 benchmark,体现出他们模型卓越的性能。
# Related Work
# Learning Instance-level Association
目前的方法分为 self-supervised 和 supervised 的策略,self-supervisied 的方法不能完整的开发出实例层面的数据,然而 supervised 的方法依赖于大量标记的数据,我们的方法 shows exceptional zero-shot association ability across diverse domains
# Segment and Track Anythin Models
在分割和追踪的方法中,例如 Deva,TAM and SAM-Track 等等,都面临 limitations,例如 poor mask progation quality due to domain gaps and the inability to handle multiple diverse objects or rapid objects entry and exit, common in scenarios like autonomous driving.
我们的方法聚焦于学习 universal association modules by leveraging SAM's rich instance segmentation knowledge.
# Method
# Preliminaries: SAM
SAM is composed of three modules:
A heavy ViT-based backbone for feature extraction.(ViT-based backbone 是指使用 Vison Transformer 作为主干网络来提取图像特征的结构。ViT 是一种基于 Transformer 的视觉模型,最初由 Google 提出,它将图像分割为小块 (patches),然后像处理序列数据一样,通过 Transformer 结构进行特征提取)
Prompt encoder: Modeling the positional information from the interactive points, box, or mask prompts.(这里是指多模态体现,可以接受不同类型的用户输入提示来指定需要分割的对象包括(点提示、框提示、文本提示,SAM 会将这些提示转化为 “提示嵌入”,并与图像嵌入结合,从而帮助模型定位并分割出目标区域。)
Mask decoder: A transformer-based decoder takes both the extracted image embedding with the concatenated output and prompt tokens for final mask prediction.(结合图像嵌入和提示嵌入并生成分割掩码)
# Matching Anythin by Segmenting Anything
Our methods consists of two key components
基于 SAM,我们得到了一个新的 pipeline:MASA,通过这个 pipeline,我们构建了一个为了 dense instance-level correspondence from a rich collection of unlabeled images 的彻底的监督方式。
我们构建了一个具有普遍性的 MASA adapter,使得能有效地 transform the features from a frozen detection or segmentation backbone for learning generalizable instance appearance representation.
Byproduct: the distillation branch of the MASA adapter can also significantly improve the efficiency of segmenting everything.
# MASA Pipeline
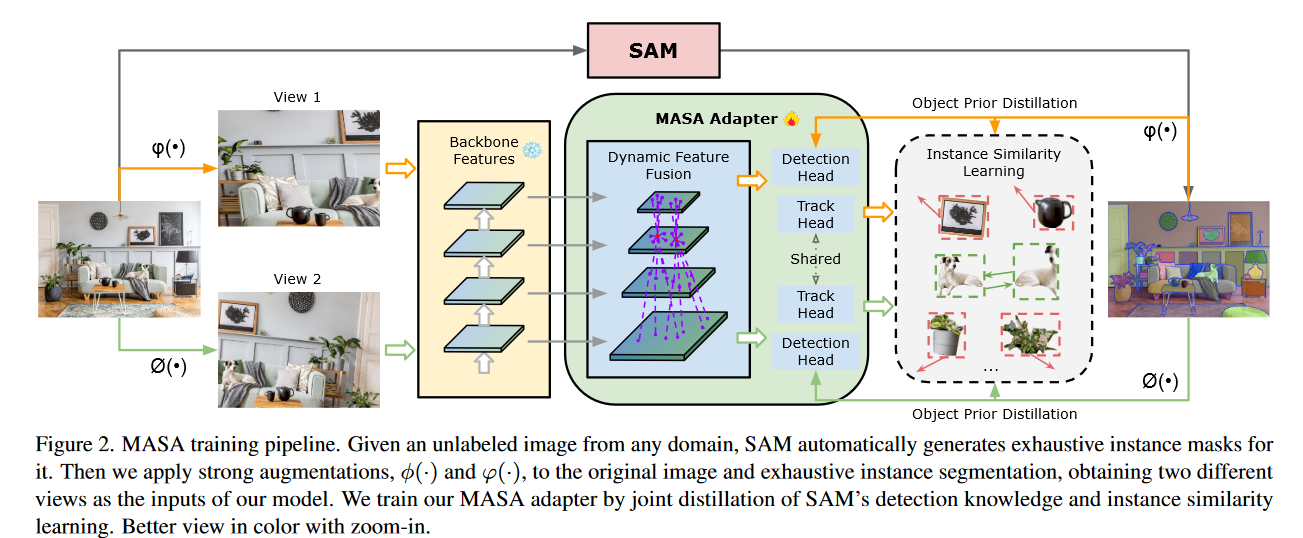
现有的方法在复杂域的多实例的数据中分辨实例的表现并不好,为了解决这个问题提出了 MASA training pipeline。
核心的目标是增加两个方面的多样性:
- training image diversity
- instance diversity
我们通过两种不同的增强模拟了视频中外观的变化,得到了两种不同的视角
\begin{equation} \mathcal{L}_{\mathcal{C}}=-\sum_{q \in Q} \log \frac{e^{\frac{\operatorname{sim}\left(q, q^{+}\right)}{\tau}}}{e^{\frac{\operatorname{sim}\left(q, q^{+}\right)}{\tau}}+\sum_{q^{-} \in Q^{-}} e^{\frac{\operatorname{sim}\left(q, q^{-}\right)}{\tau}}}, \end{equation}Here, and denote the positive and negative samples to , respectively. Positive samples are the same instance proposals being applied different and . Negative samples are from different instances. Furthermore, denotes the cosine similarity and is a temperature parameter, set to 0.07 in our experiment.
This contrastive learning formula pushes object embeddings belonging to the same instance closer while distancing embeddings from different instances.
说实话看了半天没看懂这个 MASA Pipeline 想干嘛,感觉它写的也模模糊糊的,后面看看代码再理解一下。
# MASA Adapter
MASA Adapter 在 frozen backbone features 上进行操作,然而不是所有的预处理后的特征都能在追踪目标上面有良好的表现,所以我们首先将这些 frozen backbone features 转换成 new features more suitable for tracking.
为了有效地学习 discriminative features for diffetent instances,有必要让在一个位置上的物体认识到其它位置上物体的外观,因此,我们使用了 deformable convolution 去生成 dynamic offsets and aggregate information across spatial locations and feature levels as:
\begin{equation} F(\mathcal{p})=\frac{1}{L}\sum_{j=1}^{L}\sum_{k=1}^{K}\mathcal{w}_k \cdot F^j (\mathcal{p}+\mathcal{p}_k+\Delta \mathcal{p}_k^j)\cdot \Delta m_k^j \end{equation}where represents the feature level, is the number of sampling locations for a convolutional kernel, and are the weight and predefined offsetfor the -th location respectively, and and are the learnable offset and modulation factor for the -th location at the -th feature level.
Object Prior Distillation 作为任务的辅助手段,使用 RCNN detection head 去学习对于每个 instance 包含 SAM's mask prediction 的 dounding boxes,加强了模型的精确度并提高了速度。
The MASA adapter is optimized using a combination of detection and contractive losses as .
# Inference
Figure 3 shows the test pipeline with our unified models.
# Detect and Track Anythin
Remove the MASA detection head that was learned during training. The MASA adapter then solely serves as a tracker.
We use a simple bi-softmax nearest neighbor search for accurate instance matching.
# Segment and Track Anything
With SAM, we keep the detection head.
# Testing with Given Observations
When detections are obtained from sources other than the one the MASA adapter is build upon, Our MASA adapter serves as a tracking feature provider.
# Experiments
这部分及以后的部分就不深入写了,对于课题要求的任务没有太大的关系,后面会详细写一下代码是怎么运行。
# 代码部分
# 环境
由于是第一次接触如此大规模 CV 的项目,重新搭建环境耗费了我两天共超过 20 个小时的时间,但在这个过程中也是理解了环境搭建的种种规则,对于 conda 的指令等等也是有了质的理解与提升。我也是第一次看到自己的电脑 CPU,内存倏的一下直接跑满。
下面的视频是跑出来的效果。可以看到实际跑出来的视频对比原视频大小缩小了 10 倍,效果也是比较好的。
效果可由迅雷下载查看
# 代码
# video_demo_with_text
这是程序调用的主函数,具体的调用指令如下
1 | python demo/video_demo_with_text.py demo/minions_rush_out.mp4 --out demo_outputs/minions_rush_out_outputs.mp4 --masa_config configs/masa-gdino/masa_gdino_swinb_inference.py --masa_checkpoint saved_models/masa_models/gdino_masa.pth --texts "yellow_minions" --score-thr 0.2 --unified --show_fps |
可以看到它的官方对参数的介绍:
--texts: the object class you want to track. If there are multiple classes, separate them like this:"giraffe . lion . zebra".--out: the output video path.--score-thr: the threshold for the visualize object confidence.--detector_type: the detector type. We supportmmdetandyolo-world(soon).--unified: whether to use the unified model.--postprocessing: whether to use the postprocessing. (reduce the jittering effect caused by the detector.)--show_fps: whether to show the fps.--sam_mask: whether to visualize the mask results generated by SAM.--fp16: whether to use fp16 mode.
由于我以前一直是写 C++、Java 和 Matlab 的,对 python 的语法并不是很熟悉,也算是为了以后自己的研究生生活,接下来我会利用通义千问和 ChatGPT 对代码逐块的进行解析:
1 | os.environ["TOKENIZERS_PARALLELISM"] = "false" |
os.environ 是一个字典,用于访问和修改环境变量。TOKENIZERS_PARALLELISM 是一个特定的环境变量,用于控制 Hugging Face 的 transformers 库中的 tokenizer 是否启用多线程并行处理。
将其设置为 "false" 可以禁用并行处理。这在某些情况下是有用的,例如在多进程环境中,为了避免资源竞争或过度消耗 CPU 资源。
os.path.dirname(__file__) 获取当前脚本文件所在的目录的绝对路径。os.path.join(os.path.dirname(__file__), '..') 获取当前脚本文件所在目录的父目录的绝对路径。os.path.abspath(...) 将路径转换为绝对路径。project_root 变量存储了项目的根目录路径。sys.path 是一个列表,其中包含 Python 解释器在导入模块时会搜索的路径。sys.path.insert(0, project_root) 将项目的根目录插入到 sys.path 列表的最前面,这样在导入模块时,Python 会优先从这个目录中查找模块。
1 | try: |
set_start_method 是 multiprocessing 模块中的一个函数,用于设置创建子进程的方法。'spawn' 是一种启动方法,它会在新的进程中重新启动 Python 解释器,并且只传递必要的信息来运行目标函数。这种方法适用于所有平台,包括 Windows 和 macOS 。
pass 关键字表示在捕获到异常时不做任何处理,只是简单地忽略该异常。(在第一次跑这个代码时,电脑由于开了太多的窗口,结果一跑起代码直接死机,拉都拉不回来,我估计就是这个原因)
1 | def visualize_frame(args, visualizer, frame, track_result, frame_idx, fps=None): |
调用
visualizer.add_datasample方法:- 将当前帧的编号
frame_idx作为名称,格式为'video_' + str(frame_idx)。 - 提供当前帧的图像数据
frame给image参数,这里frame[:, :, ::-1]是将图像从 BGR 格式转换为 RGB 格式,因为 OpenCV 默认读取的图像是 BGR 格式的,而许多显示或处理函数需要的是 RGB 格式。 - 通过
data_sample参数传递跟踪结果track_result[0],这通常包含了在当前帧中检测到的对象及其位置信息。 - 设置
draw_gt参数为False,意味着不会绘制真实标签(ground truth),通常用于预测或测试阶段。 show参数设为False表示不立即显示图像,可能是因为图像会被进一步处理或者保存。out_file参数设为None表明不会将图像直接保存到文件中。pred_score_thr参数用于设置预测得分的阈值,只有当对象的置信度评分超过此阈值时,才会在图像中标记出来。这个值是从args参数中获取的,args通常是一个包含多个配置项的对象。fps参数可选地提供视频的帧率信息,这对于某些类型的可视化可能是有用的。
- 将当前帧的编号
获取并返回处理后的图像:
- 使用
visualizer.get_image()获取经过上述操作后更新的图像。 - 返回这个图像,这样可以在函数外部继续使用或保存它。
- 使用
垃圾回收:
- 调用
gc.collect()进行垃圾回收,释放不再使用的内存。虽然 Python 有自动的垃圾回收机制,但在处理大量数据或长时间运行的应用程序中,显式调用垃圾回收可以帮助管理内存,特别是在循环处理视频帧等场景下。
- 调用
1 | def parse_args(): |
这段代码实现的功能和上面提到的参数的功能差不多
parser.add_argument 用于添加一个命令行参数。help 参数提供了该参数的简要说明。default 参数指定了该参数的默认值。type 参数指定了该参数的类型(如 str 、 int 、 float )。action='store_true' 表示这是一个布尔标志,如果在命令行中出现该参数,则其值为 True ,否则为 False 。
parser.parse_args() 解析命令行参数,并将它们存储在 args 对象中。return args 返回解析后的参数对象,以便在其他部分的代码中使用这些参数。
接下来就是 main 函数了
1 | args = parse_args() |
这行代码使用 assert 语句来确保 args.out 不为空。assert 语句的基本语法是:
1 | assert condition, message |
condition 是一个布尔表达式,如果为 False ,则会引发 AssertionError 。message 是一个字符串,当 condition 为 False 时,会作为错误消息的一部分打印出来。
1 | # build the model from a config file and a checkpoint file |
我们可以看到在我们调用这个 python 文件是,我们的参数为:
1 | --masa_config configs/masa-gdino/masa_gdino_swinb_inference.py --masa_checkpoint saved_models/masa_models/gdino_masa.pth |
# masa_gdino_swinb_inference
这个 config 定义了一系列的参数,非常的复杂而且难以完全的掌握,所以我直接引用了 AI 生成的对于这个代码的解释:
这段代码配置了一个复杂的深度学习模型,特别是用于目标检测和跟踪的任务。它使用了 MMDetection 框架,并且定义了多个组件来构建一个完整的模型。接下来,我会逐行解释这段代码的主要部分。
1 | _base_ = [ |
这行代码指定了基础配置文件,这些文件包含了预设的模型结构、数据集配置等。 _base_ 关键字允许继承其他配置文件中的设置。
1 | default_scope = 'mmdet' |
设置默认的作用域为 mmdet ,即 MMDetection。这有助于确保所有组件都正确地注册在这个框架下。
1 | detector = _base_.model |
这部分代码从基础配置中加载了模型( detector ),然后移除了 data_preprocessor 字段,替换成预训练权重的初始化配置,并设置了模型类型为 GroundingDINOMasa 。
1 | del _base_.model |
删除了基础配置中的 model 字段,因为已经将其赋值给了 detector 变量。
1 | model = dict( |
这是整个模型的配置字典,包含了所有组件的定义。例如:
type='MASA'定义了模型的整体类型。freeze_detector=True表示冻结检测器的参数,不进行更新。unified_backbone=True表示使用统一的主干网络。load_public_dets = False是否加载公共的检测结果。data_preprocessor配置了数据预处理的方式,包括归一化、填充等。detector是之前定义的检测器配置。masa_adapter包含了特征金字塔网络 (FPN) 和变形融合 (DeformFusion) 模块的配置。rpn_head和roi_head分别配置了区域提议网络 (RPN) 和 ROI 头,用于生成候选框和进行最终的目标检测。track_head和tracker配置了跟踪相关的头部和追踪器。
1 | inference_pipeline = [ |
定义了推理时的数据处理流程,如调整图像大小、打包输入等。
1 | # runtime settings |
这些是运行时的配置,分别对应训练、验证和测试阶段。这里没有指定训练配置,而验证和测试则指定了循环类型。
1 | default_hooks = dict( |
定义了一些默认的回调函数,比如日志记录、可视化、检查点保存等。
1 | vis_backends = [dict(type='LocalVisBackend')] |
配置了可视化的后端和可视化器,用于在训练过程中展示中间结果或调试信息。
# FPN
然而我还是没有办法理解这个代码,对于其中的某些定义我用 AI 生成了一下:
FPN(Feature Pyramid Network,特征金字塔网络)是一种用于计算机视觉任务(尤其是目标检测和分割)的通用架构。它通过构建一个金字塔式的多尺度特征图来提高模型对不同大小目标的检测能力。FPN 的核心思想是在不同层次上利用特征图的信息,从而在不同的尺度上增强特征表达。
FPN 的基本结构
底部到顶部的路径(Bottom-up Pathway):
- 这个路径通常由标准的卷积网络(如 ResNet)组成,负责提取原始输入图像的特征。随着网络深度的增加,特征图的分辨率逐渐降低,但语义信息逐渐增强。
- 每个卷积层输出的特征图可以看作是不同尺度上的特征表示,这些特征图构成了 FPN 的基础。
顶部到底部的路径(Top-down Pathway):
- 顶部到底部的路径通过自顶向下的方式逐步融合来自底部到顶部路径的特征图。具体来说,它从最高层次的特征图开始,通过上采样(通常是最近邻插值或双线性插值)将特征图恢复到更高的分辨率。
- 在每个层次上,上采样的特征图与相应层次的底部到顶部路径的特征图进行逐元素相加(或级联),形成新的特征图。
横向连接(Lateral Connections):
- 横向连接用于将底部到顶部路径的高分辨率、低语义级别的特征图与顶部到底部路径的低分辨率、高语义级别的特征图结合起来。
- 通常,横向连接会先对底部到顶部路径的特征图进行 1x1 卷积,以减少通道数并匹配顶部到底部路径的特征图的维度,然后再进行逐元素相加。
FPN 的工作流程
特征提取:
- 使用标准的卷积网络(如 ResNet)提取多尺度的特征图。假设我们有四个特征图 ,其中 具有最高的分辨率, 具有最低的分辨率。
顶部到底部的路径:
- 从最顶层的特征图 开始,通过 1x1 卷积减少通道数,得到 。
- 对 进行上采样,使其分辨率与 相同,然后与 通过 1x1 卷积后的特征图逐元素相加,得到 。
- 同样的过程继续,依次得到 $(P_3) $ 和 。
最终特征图:
- 最终得到的特征图 构成了一个特征金字塔,每个层次的特征图都具有不同的分辨率和语义信息。
- 这些特征图可以用于后续的检测或分割任务,每个层次的特征图适用于不同大小的目标。
# DeformFusion
DeformFusion 是一种用于特征融合的模块,通常在计算机视觉任务中用于增强模型的特征表示能力。与传统的特征融合方法不同, DeformFusion 引入了可变形卷积(Deformable Convolution)的概念,使得特征融合过程更加灵活和适应性强。以下是对 DeformFusion 的详细解释:
- 可变形卷积(Deformable Convolution)
可变形卷积是传统卷积的一种扩展,它允许卷积核在特征图上的位置是动态变化的,而不是固定在规则的网格上。这种动态变化的位置由偏移量(offsets)来控制,偏移量是通过一个额外的卷积层学习得到的。可变形卷积的主要优点是能够更好地捕捉不规则形状的物体和特征,从而提高模型的鲁棒性和准确性。
- DeformFusion 的概念
DeformFusion 是一种结合了可变形卷积的特征融合模块,它的主要目的是在不同层次的特征图之间进行更有效的信息交换和融合。具体来说, DeformFusion 通过以下步骤实现特征融合:
1. **输入特征图**:
DeformFusion接受多个不同层次的特征图作为输入。这些特征图通常来自不同的卷积层,具有不同的分辨率和语义信息。
2. **可变形卷积**:
- 使用可变形卷积对输入特征图进行处理。可变形卷积通过学习偏移量,使得卷积核可以在特征图上动态地选择关键区域,从而更好地捕捉不规则形状的特征。
3. **特征融合**:
- 将经过可变形卷积处理后的特征图进行融合。常见的融合方法包括逐元素相加、级联(concatenation)等。通过融合,不同层次的特征图可以互补,增强整体的特征表示能力。
- DeformFusion 的配置
在你的代码中, DeformFusion 的配置如下:
1 | masa_adapter = [ |
FPN:
type='FPN'表示这是一个特征金字塔网络(Feature Pyramid Network)。in_channels=[256, 512, 1024]表示输入特征图的通道数。out_channels=256表示输出特征图的通道数。norm_cfg=dict(type='SyncBN', requires_grad=True)表示使用同步批量归一化(SyncBN),并且参数是可训练的。num_outs=5表示输出的特征图层数。
DeformFusion:
type='DeformFusion'表示这是一个可变形特征融合模块。in_channels=256表示输入特征图的通道数。out_channels=256表示输出特征图的通道数。num_blocks=3表示使用 3 个可变形卷积块进行特征融合。
# 区域提议网络 (RPN) 和 ROI 头
区域提议网络(Region Proposal Network, RPN)和 ROI 头(Region of Interest Head)是目标检测任务中两个非常重要的组件,尤其是在两阶段检测器(如 Faster R-CNN)中。它们分别负责生成候选区域和进行目标分类与定位。下面是对这两个组件的详细解释:
- 区域提议网络(RPN)
RPN 是一种用于生成候选区域(Region Proposals)的网络,这些候选区域是可能包含目标的矩形框。RPN 的主要任务是生成高质量的候选区域,这些区域随后会被传递给后续的网络进行进一步的处理。
工作流程
1. **特征提取**:
- RPN 通常接在卷积神经网络(如ResNet)的后面,输入是卷积网络提取的特征图。
- 特征图的每个位置都会生成一组候选区域(锚框,Anchors)。
2. **锚框生成**:
- 锚框是预先定义的一组矩形框,具有不同的尺度和宽高比。
- 例如,一个特征图上的每个位置可能生成9个不同尺度和宽高比的锚框。
3. **分类和回归**:
- RPN 对每个锚框进行分类和回归:
- **分类**:判断每个锚框是否包含目标(前景或背景)。这通常通过一个二分类的全连接层实现。
- **回归**:调整锚框的位置和大小,使其更接近真实的目标框。这通常通过一个回归层实现,输出四个参数(Δx, Δy, Δw, Δh),表示锚框相对于真实框的偏移量。
4. **非极大值抑制(NMS)**:
- 生成的候选区域可能会有很多重叠的情况,因此需要进行非极大值抑制(Non-Maximum Suppression, NMS)来筛选出高质量的候选区域。
- NMS 根据分类得分和重叠度(IOU)来保留得分最高的候选区域,去除重叠较大的区域。
优势
- 高效生成候选区域:RPN 通过卷积操作生成候选区域,计算效率高,适用于大规模数据集。
- 与检测网络共享特征:RPN 和后续的检测网络可以共享卷积特征,减少了计算量。
- ROI 头(Region of Interest Head)
ROI 头 是用于对候选区域进行分类和精确定位的网络组件。它接收 RPN 生成的候选区域,并对其进行进一步处理,最终输出目标类别和精确的边界框。
工作流程
1. **ROI池化(ROI Pooling)**:
- 将RPN生成的候选区域映射到特征图上,并进行池化操作,将不同大小的候选区域统一到固定大小的特征图。
- 常见的池化方法有ROI Pooling和ROI Align。
2. **特征提取**:
- 对池化后的特征图进行进一步的卷积操作,提取更高级的特征。
3. **分类和回归**:
- **分类**:通过一个全连接层对每个候选区域进行分类,输出目标类别的概率分布。
- **回归**:通过另一个全连接层对每个候选区域进行回归,输出精确的边界框坐标。
4. **非极大值抑制(NMS)**:
- 对分类和回归后的结果进行NMS,去除重叠较大的边界框,保留得分最高的目标框。
配置示例
在你的代码中, rpn_head 和 roi_head 的配置如下:
1 | rpn_head=dict( |
RPN Head:
type='RPNHead':表示这是一个 RPN 头部。in_channels=256和feat_channels=256:输入和特征图的通道数。anchor_generator:定义了锚框的生成方式,包括尺度、宽高比和步幅。bbox_coder:定义了边界框编码和解码的方式。loss_cls和loss_bbox:定义了分类和回归的损失函数。
ROI Head:
type='StandardRoIHead':表示这是一个标准的 ROI 头部。bbox_roi_extractor:定义了 ROI 池化的方式,包括池化层的类型、输出大小和特征图的步幅。bbox_head:定义了边界框头部,包括全连接层的输出通道数、ROI 特征的大小、类别数、边界框编码方式和损失函数。
总结
- RPN:负责生成高质量的候选区域,通过分类和回归操作调整锚框的位置和大小。
- ROI Head:对候选区域进行进一步的分类和精确定位,输出最终的目标类别和边界框。
# gdino_masa.pth
至于这个参数,我也不知道这是个啥,只有一些推测:
- 文件扩展名 .pth:
- .pth 是 PyTorch 模型权重文件的标准扩展名。这种文件通常包含模型的参数(权重和偏置),有时还包括优化器的状态和其他元数据。
- 文件内容:
- 文件内容是二进制格式,包含模型的权重和偏置等参数。
这些参数是通过训练过程学习到的,用于初始化模型,使其在特定任务上表现良好。
- 文件内容是二进制格式,包含模型的权重和偏置等参数。
# init_masa
这段代码定义了一个函数 init_masa ,用于从配置文件初始化一个统一的 MASA 检测器模型。该函数接受多个参数,包括配置文件路径、预训练权重文件路径、颜色调色板、设备以及配置选项。下面是对这段代码的逐行解释:
# 函数定义和参数
1 | def init_masa( |
config:配置文件路径、Path对象或Config对象。checkpoint:预训练权重文件路径。如果为None,模型将不会加载任何权重。palette:用于可视化的颜色调色板,默认为"none"。device:模型将要部署的设备,默认为"cuda:0"。cfg_options:用于覆盖配置文件中某些设置的字典。
# 文档字符串
1 | """ |
# 处理配置文件
1 | if isinstance(config, (str, Path)): |
- 检查
config是否为字符串或Path对象,如果是,则使用Config.fromfile方法读取配置文件。 - 如果
config不是Config对象,抛出类型错误。
# 处理配置选项
1 | with_backbone = config.model.get("backbone", False) |
- 检查配置文件中是否有
backbone部分。 - 如果有
backbone部分,且cfg_options不为None,则将cfg_options合并到配置文件中。 - 如果
cfg_options为None且backbone部分中有init_cfg,则将其设置为None。 - 如果没有
backbone部分,处理detector部分,逻辑类似。
# 初始化默认作用域
1 | scope = config.get("default_scope", "mmdet") |
- 获取配置文件中的默认作用域,默认为
"mmdet"。 - 如果存在默认作用域,初始化默认作用域。
# 构建模型
1 | model = MODELS.build(config.model) |
- 使用
MODELS.build方法根据配置文件构建模型。 - 将模型中的同步批量归一化层转换为普通的批量归一化层。
# 加载预训练权重
1 | if checkpoint is None: |
- 如果
checkpoint为None,发出警告并使用 COCO 数据集的类别。 - 否则,加载预训练权重文件,并从权重文件的元数据中获取数据集元信息(如类别和调色板)。
# 设置调色板
1 | if palette != "none": |
- 如果
palette不为"none",设置模型的调色板。 - 如果
palette为"none"且模型的元信息中没有调色板,发出警告并使用随机调色板。
# 保存配置和设置设备
1 | model.cfg = config # save the config in the model for convenience |
- 将配置文件保存到模型中,便于后续使用。
- 将模型移动到指定的设备上。
- 将模型设置为评估模式。
# 返回模型
1 | return model |
- 返回初始化好的模型。
# 总结
init_masa 函数的主要功能是从配置文件和预训练权重文件中初始化一个 MASA 检测器模型,并设置相关参数(如调色板、设备等),返回一个准备好的模型对象。这个函数在实际使用中可以帮助用户快速加载和配置模型,以便进行目标检测任务。
好的现在回到 video_demo_with_text 这个代码
1 | if args.sam_mask: |
这段代码的主要功能是根据命令行参数 args.sam_mask 判断是否需要加载一个名为 SAM(Segment Anything Model)的模型。如果需要加载,它会执行一系列操作来初始化和配置 SAM 模型。
1 | video_reader = mmcv.VideoReader(args.video) |
使用 mmcv 的 VideoReader 类读取视频文件,每一帧将依次处理。
1 | #### parsing the text input |
这段代码的主要功能是解析文本输入,并根据是否存在文本输入来构建测试管道和配置模型的可视化器。下面是对这段代码的逐行解释:
获取文本输入:从命令行参数
args中获取texts,这是一个可能包含用户提供的文本列表的变量。构建测试管道:
- 如果
texts不为None,即用户提供了文本输入,调用build_test_pipeline函数并传入masa_model.cfg和with_text=True参数,构建一个支持文本输入的测试管道。 - 如果
texts为None,即用户没有提供文本输入,调用build_test_pipeline函数并传入masa_model.cfg参数,构建一个不支持文本输入的测试管道。
- 如果
配置可视化器:
- 如果
texts不为None,即用户提供了文本输入,将texts赋值给masa_model.cfg.visualizer['texts'],这样可视化器将使用用户提供的文本。 - 如果
texts为None,即用户没有提供文本输入,将det_model.dataset_meta['classes']赋值给masa_model.cfg.visualizer['texts'],这样可视化器将使用数据集中定义的类别名称。
- 如果
1 | # init visualizer |
这段代码的主要功能是初始化可视化器,并根据命令行参数配置可视化器的属性。此外,如果指定了输出视频文件,还会初始化视频写入器。下面是对这段代码的逐行解释:
设置保存目录:将命令行参数
args.save_dir的值赋给masa_model.cfg.visualizer['save_dir'],指定可视化结果的保存目录。设置线条宽度:将命令行参数
args.line_width的值赋给masa_model.cfg.visualizer['line_width'],指定绘制边界框时的线条宽度。设置透明度:如果命令行参数
args.sam_mask为True,将masa_model.cfg.visualizer['alpha']设置为0.5,表示在绘制分割掩码时使用的透明度。构建可视化器:使用
VISUALIZERS.build方法根据masa_model.cfg.visualizer配置构建一个可视化器对象visualizer。VISUALIZERS是一个注册表,包含了多种可视化器的构建方法。初始化视频写入器:
- 如果命令行参数
args.out不为None,表示需要将处理后的视频保存到指定的输出文件。 fourcc = cv2.VideoWriter_fourcc(*'mp4v'):设置视频编解码器为mp4v。video_writer = cv2.VideoWriter(args.out, fourcc, video_reader.fps, (video_reader.width, video_reader.height)):创建一个cv2.VideoWriter对象video_writer,用于将处理后的帧写入输出视频文件。参数包括输出文件路径、编解码器、帧率(从video_reader获取)、视频宽度和高度(从video_reader获取)。
- 如果命令行参数
1 | frame_idx = 0 |
这段代码的主要功能是处理视频流中的每一帧,进行目标检测和跟踪,并将结果存储起来。以下是逐行解释:
# 初始化变量
1 | frame_idx = 0 |
frame_idx:初始化帧索引为 0,用于记录当前处理的帧编号。instances_list:初始化一个空列表,用于存储每帧的跟踪结果。frames:初始化一个空列表,用于存储每帧的原始图像。fps_list:初始化一个空列表,用于存储每帧的处理速度(FPS)。
# 处理视频流
1 | for frame in track_iter_progress((video_reader, len(video_reader))): |
track_iter_progress:一个函数,用于跟踪视频读取进度。video_reader是视频读取器对象,len(video_reader)是视频的总帧数。
# 统一模型处理
1 | if args.unified: |
- 条件判断:如果命令行参数
args.unified为True,表示使用统一模型进行处理。 inference_masa:调用inference_masa函数进行目标检测和跟踪。参数包括:masa_model:模型对象。frame:当前帧的图像。frame_id:当前帧的索引。video_len:视频的总帧数。test_pipeline:测试管道。text_prompt:文本提示。fp16:是否使用半精度浮点数。detector_type:检测器类型。show_fps:是否显示 FPS。
- 处理 FPS:如果
args.show_fps为True,track_result将包含 FPS 信息,将其分离出来。
# 非统一模型处理
1 | else: |
- 条件判断:如果命令行参数
args.unified为False,表示使用非统一模型进行处理。 inference_detector:调用inference_detector函数进行目标检测。参数包括:det_model:检测模型对象。frame:当前帧的图像。text_prompt:文本提示。test_pipeline:测试管道。fp16:是否使用半精度浮点数。
# 执行非极大值抑制(NMS)
1 | det_bboxes, keep_idx = batched_nms(boxes=result.pred_instances.bboxes, |
batched_nms:执行非极大值抑制(NMS),去除冗余的检测框。参数包括:boxes:检测框的坐标。scores:检测框的置信度分数。idxs:检测框的类别标签。class_agnostic:是否进行类别无关的 NMS。nms_cfg:NMS 的配置参数,包括类型、IoU 阈值等。
# 更新检测结果
1 | det_bboxes = torch.cat([det_bboxes, |
- 更新检测框:将保留的检测框和对应的置信度分数拼接在一起。
- 更新标签:保留的检测框对应的类别标签。
# 进行目标跟踪
1 | track_result = inference_masa(masa_model, frame, frame_id=frame_idx, |
inference_masa:调用inference_masa函数进行目标跟踪。参数包括:masa_model:模型对象。frame:当前帧的图像。frame_id:当前帧的索引。video_len:视频的总帧数。test_pipeline:测试管道。det_bboxes:检测框的坐标。det_labels:检测框的类别标签。fp16:是否使用半精度浮点数。show_fps:是否显示 FPS。
- 处理 FPS:如果
args.show_fps为True,track_result将包含 FPS 信息,将其分离出来。
# 更新帧索引
1 | frame_idx += 1 |
- 更新帧索引:将帧索引加 1,表示处理下一帧。
# 处理跟踪结果
1 | if 'masks' in track_result[0].pred_track_instances: |
- 检查掩码:如果跟踪结果中包含掩码,并且掩码数量大于 0,将掩码堆叠成一个张量,并将其移动到 CPU 上转换为 NumPy 数组。
# 更新检测框的数据类型
1 | track_result[0].pred_track_instances.bboxes = track_result[0].pred_track_instances.bboxes.to(torch.float32) |
- 转换数据类型:将检测框的坐标转换为
float32类型。
# 存储结果
1 | instances_list.append(track_result.to('cpu')) |
- 存储跟踪结果:将当前帧的跟踪结果(转换为 CPU 上的张量)添加到
instances_list中。 - 存储原始帧:将当前帧的原始图像添加到
frames中。 - 存储 FPS:如果
args.show_fps为True,将当前帧的 FPS 添加到fps_list中。
# 总结
这段代码的主要功能是处理视频流中的每一帧,进行目标检测和跟踪,并将结果存储起来。具体步骤包括:
- 初始化变量:初始化帧索引、结果列表、帧列表和 FPS 列表。
- 处理视频流:遍历视频的每一帧。
- 统一模型处理:如果使用统一模型,调用
inference_masa进行检测和跟踪。 - 非统一模型处理:如果使用非统一模型,先调用
inference_detector进行检测,再执行 NMS 去除冗余检测框,最后调用inference_masa进行跟踪。 - 更新帧索引:增加帧索引。
- 处理跟踪结果:处理跟踪结果中的掩码和检测框。
- 存储结果:将当前帧的跟踪结果、原始帧和 FPS 存储起来。
那么问题来了, inference_masa 是什么?
# inference_masa
1 | def inference_masa( |
这段代码定义了一个函数 inference_masa ,用于使用 MASA 模型对图像进行推理,返回跟踪数据样本。函数接受多个参数,包括模型、图像、帧 ID、视频长度、测试管道、文本提示、自定义实体、检测框、标签、是否使用半精度浮点数、检测器类型和是否显示 FPS。下面是对这段代码的详细解释:
# 函数定义和参数
1 | def inference_masa( |
model:已经加载的目标跟踪模型。img:输入的图像,类型为np.ndarray。frame_id:当前帧的 ID。video_len:视频的总帧数。test_pipeline:测试数据处理管道,可选参数。text_prompt:文本提示,可选参数。custom_entities:是否使用自定义实体,可选参数,默认为False。det_bboxes:预检测的边界框,可选参数。det_labels:预检测的标签,可选参数。fp16:是否使用半精度浮点数,可选参数,默认为False。detector_type:检测器类型,可选参数,默认为"mmdet"。show_fps:是否显示 FPS,可选参数,默认为False。
# 函数文档字符串
1 | """ |
- 文档字符串:描述了函数的功能、参数和返回值。
# 准备数据
1 | data = dict( |
- 数据字典:准备输入数据的字典。
img:将图像转换为float32类型,并放入列表中。frame_id:当前帧的 ID。ori_shape:图像的原始形状(高度和宽度)。img_id:图像的唯一标识符,通常是帧 ID 加 1。ori_video_length:视频的总帧数。
# 添加文本提示
1 | if text_prompt is not None: |
- 条件判断:如果提供了文本提示,根据检测器类型(
mmdet或yolo-world)将文本提示和自定义实体添加到数据字典中。
# 应用测试管道
1 | data = test_pipeline(data) |
- 测试管道:使用
test_pipeline对数据进行预处理。
# 前向传播模型
1 | with torch.no_grad(): |
- 禁用梯度计算:使用
torch.no_grad()禁用梯度计算,减少内存消耗。 - 数据整理:使用
default_collate将数据整理成模型所需的格式。 - 添加检测框:如果提供了检测框和标签,将它们添加到数据样本中。
# 测量 FPS
1 | if show_fps: |
- 测量开始时间:如果
show_fps为True,记录前向传播的开始时间。 - 前向传播:使用
autocast自动选择精度(如果fp16为True,则使用半精度浮点数)进行前向传播。 - 测量结束时间:记录前向传播的结束时间。
- 计算 FPS:计算并返回 FPS。
- 返回结果和 FPS:返回推理结果和 FPS。
# 不测量 FPS
1 | else: |
- 前向传播:如果不测量 FPS,直接进行前向传播。
- 返回结果:返回推理结果。
# 总结
这段代码的主要功能是使用 MASA 模型对图像进行推理,返回跟踪数据样本。具体步骤包括:
- 准备数据:将图像和相关信息组织成数据字典。
- 添加文本提示:如果提供了文本提示,根据检测器类型将其添加到数据字典中。
- 应用测试管道:使用测试管道对数据进行预处理。
- 前向传播模型:禁用梯度计算,整理数据,进行前向传播。
- 测量 FPS:如果需要,测量并返回 FPS。
- 返回结果:返回推理结果和(可选的)FPS。
希望这些解释能帮助你更好地理解这段代码的功能和作用。如果你有任何进一步的问题,欢迎随时提问!
让我们再次回到 video_demo-with_text 的代码
1 | if not args.no_post: |
这段代码的主要功能是在完成目标检测和跟踪后,进行后处理、生成掩码、可视化结果,并将结果保存到输出视频文件中。下面是逐段解释:
# 后处理跟踪结果
1 | if not args.no_post: |
- 条件判断:如果命令行参数
args.no_post为False,表示需要进行后处理。 - 后处理:调用
filter_and_update_tracks函数对instances_list进行过滤和更新。参数包括:instances_list:所有帧的跟踪结果列表。(frame.shape[1], frame.shape[0]):当前帧的宽度和高度。
# 使用 SAM 生成掩码
1 | if args.sam_mask: |
- 条件判断:如果命令行参数
args.sam_mask为True,表示需要生成掩码。 - 生成掩码:
- 遍历帧:使用
tqdm显示进度条,遍历所有帧和对应的跟踪结果。 - 移动数据到设备:将
track_result移动到指定设备(通常是 GPU)。 - 过滤低置信度实例:仅保留置信度高于
args.score_thr的实例。 - 获取检测框:提取检测框
input_boxes。 - 跳过无检测框的帧:如果当前帧没有检测框,跳过该帧。
- 设置图像:使用
sam_predictor.set_image设置当前帧的图像。 - 变换检测框:使用
sam_predictor.transform.apply_boxes_torch变换检测框。 - 生成掩码:调用
sam_predictor.predict_torch生成掩码。 - 更新掩码:将生成的掩码添加到
track_result中,并更新instances_list。
- 遍历帧:使用
# 可视化结果
1 | if args.out: |
- 条件判断:如果命令行参数
args.out不为None,表示需要将结果保存到输出视频文件。 - 多进程可视化:
- 确定核心数:计算可用的核心数,最多使用 16 个核心。
- 显示核心数:打印使用的核芯数。
- 创建进程池:使用
Pool创建多进程池。 - 调用可视化函数:
- 如果
args.show_fps为True,调用visualize_frame函数,传递args、visualizer、frame、track_result、idx和fps。 - 如果
args.show_fps为False,调用visualize_frame函数,传递args、visualizer、frame、track_result和idx。
- 如果
- 写入视频:遍历处理后的帧,将每一帧写入视频文件。注意
frame[:, :, ::-1]是将图像从 RGB 格式转换为 BGR 格式,因为 OpenCV 使用 BGR 格式。
# 释放视频写入器
1 | if video_writer: |
- 释放资源:如果
video_writer不为None,释放视频写入器资源。
# 完成
1 | print('Done') |
- 打印完成信息:打印 “Done” 表示处理完成。
# 总结
这段代码的主要功能是:
- 后处理跟踪结果:如果需要,对跟踪结果进行过滤和更新。
- 生成掩码:如果需要,使用 SAM 模型生成掩码并更新跟踪结果。
- 可视化结果:使用多进程并行处理,将跟踪结果可视化并保存到输出视频文件中。
- 释放资源:释放视频写入器资源。
- 打印完成信息:打印处理完成的信息。
希望这些解释能帮助你更好地理解这段代码的功能和作用。如果你有任何进一步的问题,欢迎随时提问!
# 后记
至此针对这个文件的操作的代码已经全部解析完毕,很正常的是看上去我现在完全没有搞懂它究竟怎么实现的,所以会继续针对论文结合代码进行一边梳理,估计那个时候就能全部搞懂了。